
 Мы попытались ответить на вопрос, каким образом стриминг-сервисы составляют для нас рекомендательные плейлисты. Спойлер: оказывается, это очень сложно.
Мы попытались ответить на вопрос, каким образом стриминг-сервисы составляют для нас рекомендательные плейлисты. Спойлер: оказывается, это очень сложно.
Каждый понедельник более 100 млн пользователей Spotify получают свежий плейлист под названием «Discover Weekly». Это персональный сборник из 30 новых для слушателя песен, которые, как считает сервис, скорее всего, понравятся пользователю.
Так выглядит плейлист «Discover Weekly»:
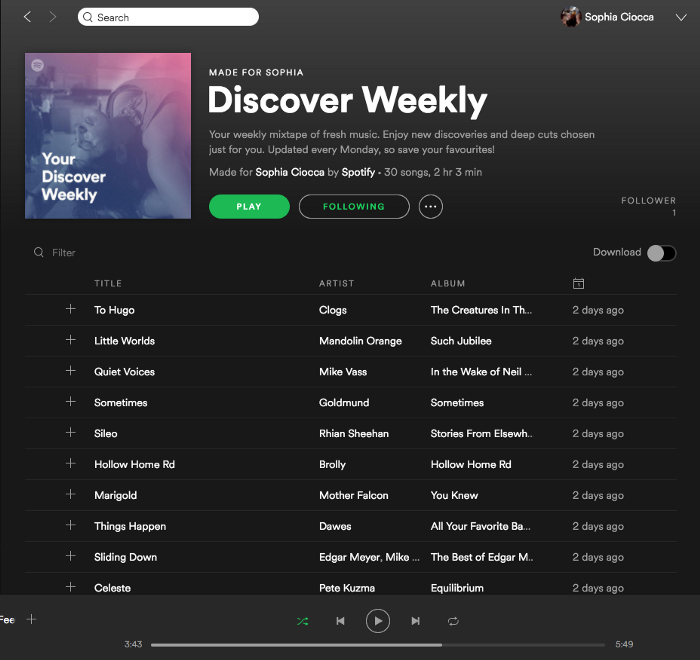
Плейлист «Discover Weekly» от Spotify
Популярность подобных рекомендаций побудила Spotify вложить больше ресурсов в разработку алгоритмов создания плейлистов.
Каким образом Spotify еженедельно отбирает для каждого пользователя по 30 песен? Для ответа на этот вопрос обратимся к истории рекомендательных сервисов с музыкой.
Краткая история музыкальных рекомендаций

В нулевые сервис Songza запустил функцию музыкальных онлайн-рекомендаций, используя живых кураторов. Команда «музыкальных экспертов» составляла, по мнению руководства сервиса, грамотные, но неперсонализированные плейлисты, распределяя их по настроениям и жанрам. Позже подобную стратегию возьмет на вооружение сервис Beats Music, который в 2015-м перевоплотится в Apple Music.
Система живых кураторов работала хорошо, но она основывалась на субъективном выборе экспертов и поэтому не могла учитывать индивидуальный вкус каждого пользователя. В какой-то момент Songza перестал работать автономно, став частью Google Play Music.
Наряду с Songza одним из оригинальнейших игроков в сфере музыкальных рекомендаций в нулевые был сервис Pandora. Его авторы придумали присваивать каждой песне набор тэгов. Группа людей слушала музыку, собирала тэги и помечала ими каждую песню. Этот метод позволял с легкостью составлять плейлисты похожей музыки.
Примерно в то же время была создана аналитическая платформа The Echo Nest, которая отличалась радикальным подходом к персонализации музыки. The Echo Nest использовала алгоритмы для анализа музыки и текста песен для создания персональных рекомендаций. Позже этот сервис был куплен Spotify.
Другим способом «рекомендательную» задачу решил до сих пор существующий сервис Last.fm, который для создания подборок использовал систему коллаборативной фильтрации.
В чем же особенность Spotify, спросите вы?
Spotify использует три модели рекомендаций
На самом деле представители крупнейшего стриминга не изобретали собственный революционный метод создания рекомендательных плейлистов. Вместо этого компания соединила лучшие подобные стратегии других сервисов. Получился уникальный и мощный исследовательский механизм.
Для создания «Discovery Weekly» сервис использует три модели:
- Коллаборативная фильтрация (метод Last.fm), которая анализирует вашу модель поведения и других.
- Обработка естественного языка (ОЕЯ) для анализа текста.
- Аудиомодели, которые анализируют аудиофайлы.
Кратко рассмотрим работу каждого метода.
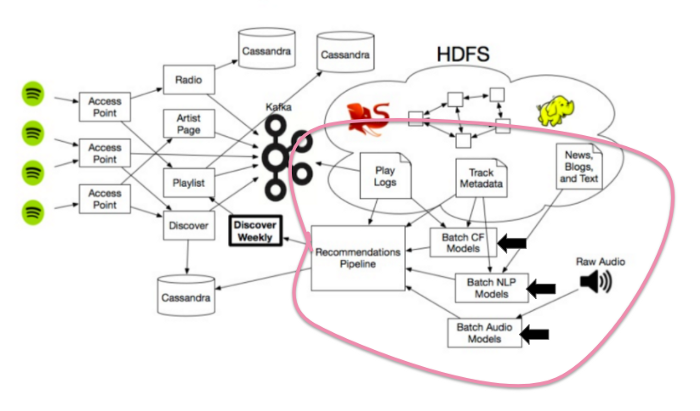
Рекомендационная модель #1: Коллаборативная фильтрация

Когда слышишь фразу «коллаборативная фильтрация», на ум обычно приходит компания Netflix как одна из первых, кто использовал такую модель рекомендаций. Netflix анализирует оценочные рейтинги пользователей и с их помощью подбирает кино для зрителей со схожими вкусами.
После успеха Netflix коллаборативная фильтрация быстро распространилась, став стартовой точкой для всех, кто занимается моделями рекомендаций.
В отличие от Netflix, Spotify не имеет системы рейтинга, который позволил бы пользователям ставить музыке оценки. База данных Spotify строится на основе косвенного фидбэка — в особенности количества прослушиваний и других стриминг-данных, например истории действий пользователя (сохранил ли он песню к себе в плейлист, посетил ли страницу артиста, песню которого слушал, и так далее).
Как работает коллаборативная фильтрация на практике? Вот небольшая иллюстрация:

Что происходит на картинке? У каждого собеседника есть предпочтения: тому, кто слева, нравятся треки P, Q, R и S, а его сосед предпочитает композиции Q, R, S и T.
Коллаборативная фильтрация обрабатывает эту информацию следующим образом:
«Хммм… Вам обоим нравятся три трека — Q, R и S, — поэтому у вас схожие вкусы. Исходя из этого, вам вполне могут понравиться треки друг друга, которые вы до этого не слушали».
После этого система предлагает собеседнику справа послушать трек P (он не упомянул эту песню, так как не слушал ее раньше, но трек есть в плейлисте собеседника). Соседу слева предлагается послушать трек T ровно по той же причине.
Но как Spotify использует эту концепцию на деле? Как рассчитываются миллионы предложений, основанных на миллионах предпочтений пользователей?
Благодаря математическим матрицам, выполненным в библиотеках Python.
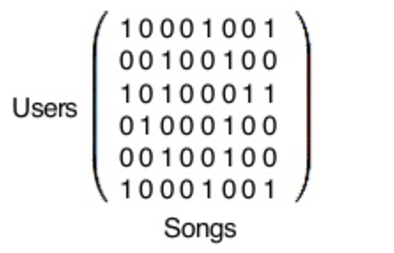
Матрица, которую вы видите, — гигантская. Каждый горизонтальный ряд представляет одного из 140 миллионов пользователей Spotify (если вы один из них, вы в матрице). Каждый вертикальный ряд представляет одну из 30 миллионов песен в базе данных Spotify.
Библиотека Python проходит через длинную сложную формулу:
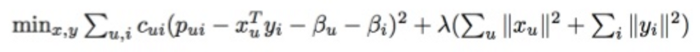
Немного сложной математики…
Когда библиотека заканчивает расчет, нам даются два вектора, показанных здесь в виде X и Y. X — это пользовательский вектор, демонстрирующий вкус одного пользователя, а Y — песенный вектор, презентующий данные одной-единственной песни.
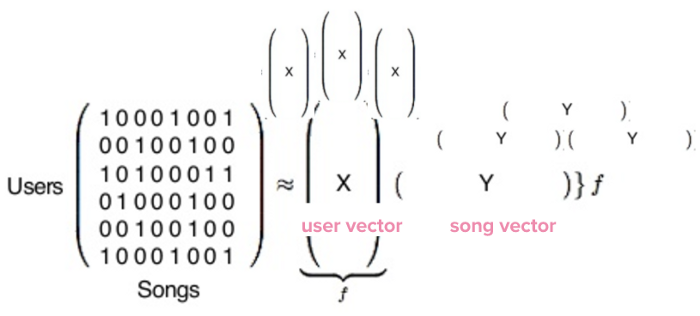
Матрица производит два типа векторов: пользовательский и песенный.
Теперь у нас 140 миллионов пользовательских векторов и 30 миллионов песенных векторов. Содержание их — простой набор чисел, бесполезных сами по себе, но очень эффективных при сравнении.
Чтобы выяснить, с какими пользователями у вас больше всего совпадают вкусы, коллаборативная фильтрация сравнивает ваш вектор с векторами других пользователей, пытаясь найти самое большое количество совпадений. То же самое происходит с вектором Y, песнями: вы можете сравнить вектор одной песни с другими и найти наиболее схожие.
Коллаборативная фильтрация работает хорошо, но в Spotify знали, что можно улучшить систему, добавив еще один механизм под названием ОЕЯ.
Рекомендационная модель #2. Обработка естественного языка (ОЕЯ)
Источник базы данных для этой модели заключен в текстовой информации о треке, новостях, статьях о нем, упоминаниях в блогах и так далее.

Обработка естественного языка — способность компьютера понимать человеческую речь. Это гигантское поле информации, которое проходит через «чувственную аналитику» API.
Объяснение работы механизма ОЕЯ выходит за рамки этой статьи, но если вкратце, Spotify бродит в сети и постоянно ищет посты, а также другие тексты о той или иной музыке. Это делается для того, чтобы понять, что и какими словами говорят люди о конкретном артисте или песне. Кроме того, сервис смотрит, какие еще артисты и песни всплывают в таких описаниях.
Неизвестно, по какому принципу Spotify выбирает данные для текстовой базы, но похожей формулой пользуется сервис The Echo Nest. Он берет данные и превращает их в то, что называется «культурными векторами», или «главными особенностями».
Каждый исполнитель и песня имеют тысячи особенностей, которые меняются ежедневно. Каждая особенность имеет определенную значимость, которая корректируется в соответствии с ее релевантностью — грубо говоря, вероятностью того, что кто-то опишет музыку или исполнителя этим словом.
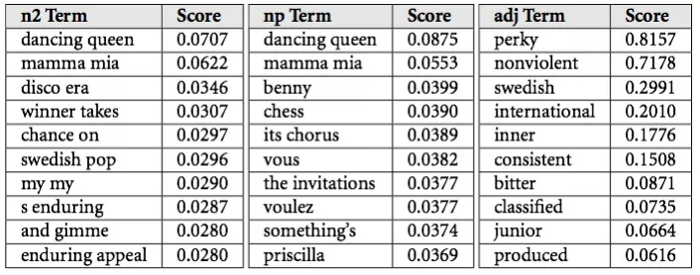
Подобно коллаборативной фильтрации, ОЕЯ-модель использует описания и их значимость для создания вектора, который представляет собой собрание всех данных о песне. Он и позволяет понять степень схожести двух и более треков.
Рекомендационная модель #3: Модель с аудиофайлами
Несмотря на эффективную совместную работу первых двух моделей, Spotify ввел третий алгоритм для улучшения точности музыкальных рекомендаций. В отличие от первых двух, модель аудиофайлов позволяет учитывать свежезагруженные песни.
Например, песня вашего друга была залита в Spotify. Возможно, у нее только 50 прослушиваний, эта выборка слишком мала для коллаборативной фильтрации. Кроме того, допустим, песня пока никак не освещена в сети, так что она пройдет и мимо модели ОЕЯ. И вот тут в дело вступает модель аудиофайлов.
Она работает без всякой дискриминации по отношению к менее популярным трекам. Благодаря этому алгоритму песня вашего друга может оказаться в «Discover Weekly» наряду с популярными треками.
Но как анализируются такие аудиоданные?
Тут на помощь приходит сверточная нейронная сеть.
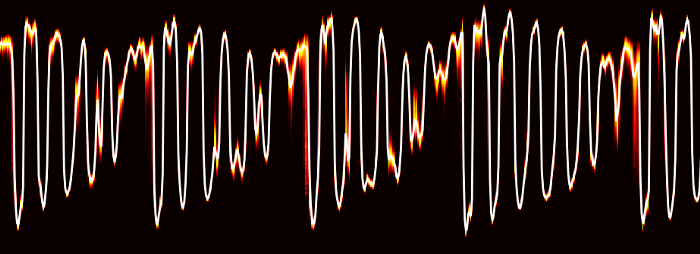
Она используется также в программах по распознаванию лиц. Для задач Spotify сеть заточили под работу с аудиоданными вместо пикселей. Ниже — пример того, как работает такая система.
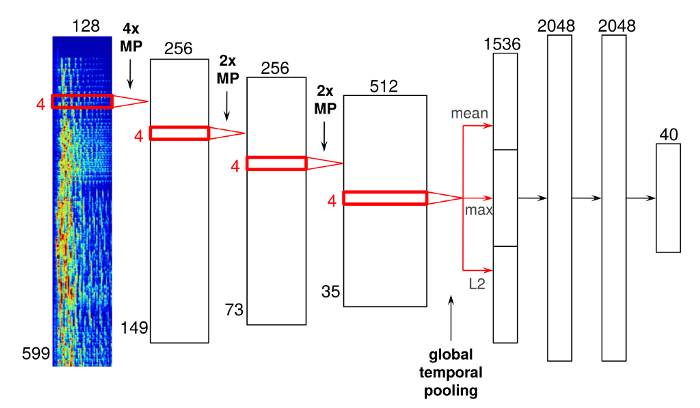
У этой нейронной сети четыре сверточных слоя (тонкие ряды слева) и три плотных узких слоя (справа). Проходы сквозь столбцы — временная частота аудиофрагментов, которые соединяются друг с другом и образуют спектрограмму.
Аудио проходит через эти сверточные слои, и после прохождения последнего можно увидеть слой «главного временного отбора». Он захватывает всю временную ось, эффективно рассчитывая статистику усвоенных особенностей трека за время его звучания.
Иными словами, проход через каждый слой дает программе небольшой срез данных, которые на финальном слое объединяются в единый массив информации.
После их обработки нейронная сеть выпускает некое «понимание» песни, которое включает в себя такие характеристики, как ее размер, гармония, форма, темп и громкость. Ниже показан набор информации, которую алгоритм получил из 30-секундного отрывка композиции «Around the World» Daft Punk.
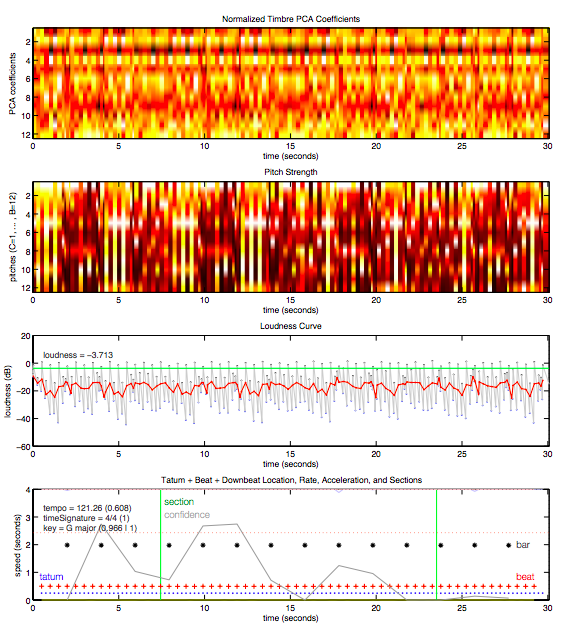
Считывание ключевых характеристик тех или иных песен позволяет Spotify понять фундаментальную схожесть между различными треками. После завершения этого процесса пользователь получает свой долгожданный «Discover Weekly».
Теперь вы знаете, какая сложная система кроется за каждой новой подборкой из 30 треков в Spotify.
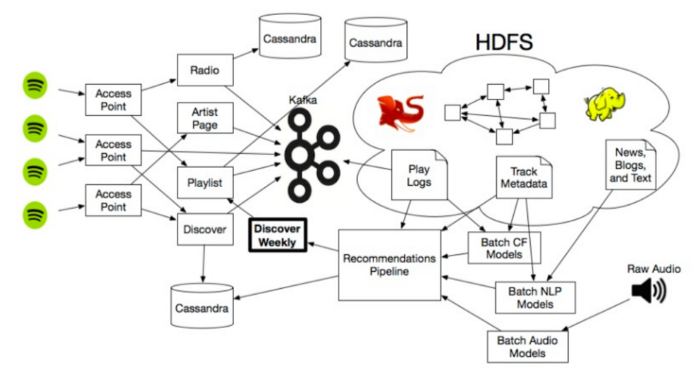
ИСТОЧНИК: Medium
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.



